Sobrevivientes del Titanic
Parte I: Entendiendo los datos
Desde la página de Kaggle he descargado la base de datos de sobrevivientes del Titanic. En esta página se propone el desafío de predecir, utilizando las herramientas del machine learning, qué tipos de pasajeros (hombre, mujer, niño, adulto, clase en la que se viajaba) tienen la mayor probabilidad de sobrevivir a la tragedia.
En esta primera parte del proyecto, utilizaré las librerías de Python llamadas Pandas, NumPy, Matplotlib y Seaborn para revisar, visualizar y entender la base de datos.
Se comienza importando las librerías mencionadas:
# Librerías para analizar los datos
import pandas as pd
import numpy as np
# Librerías para visualizar los datos
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
Luego se carga la base de datos train.csv obtenida desde kaggle y se visualizan los encabezados de columna:
# Cargar la base de datos
data = pd.read_csv('/.../train.csv')
# Visualizar los encabezados de las columnas
print(data.columns.values)
# Outputs
['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch'
'Ticket' 'Fare' 'Cabin' 'Embarked']
¿Cuál es la definición de las variables de la base de datos?
- PassengerId: Id del pasajero
- Survived: sobreviviente, No = 0, Sí = 1
- Pclass: clase del ticket, primera = 1, segunda = 2 y tercera = 3
- Name: nombre del pasajero
- Sex: sexo del pasajero, hombre = male, mujer = female
- Age: edad del pasajero en años. La edad es fraccional si es menor a un año y si es estimada se presenta de la forma xx.5
- SibSp: cantidad de hermanos(as) a bordo
- Parch: cantidad de padres a bordo
- Ticket: número del ticket
- Fare: tarifa pagada para abordar
- Cabin: número de la cabina
- Embarked: puerto de embarcación, C = Cherbourg, Q = Queenstown, S = Southampton
Una visión de las primeras filas de la tabla:
# Vista previa de los datos
data.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Y una vista de los últimos datos que contiene la base de datos:
# Vista previa de las filas finales
data.tail()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Para conocer el tipo de datos que almacena la base y la existencia de valores nulos:
# Tipo de datos y valores nulos
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
De la información anterior se concluye que se tiene registros de 891 pasajeros, donde los campos de edad (Age), cabina (Cabin) y embarcado (Embarked) contienen valores nulos.
Es posible conocer algunos estadísticos típicos para las variables numéricas:
# Algunos estadísticos para las variables de tipo numérico (integer y float)
data.describe()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Se observa que había pasajeros con edades menores al año de vida y otros que alcanzan los 80 años. En promedio, la edad de los pasajeros era cercana a los 30 y el 75% de la muestra de pasajeros no supera los 38 años de edad.
Respecto de la tarifa (Fare) que se pagó, hubo pasajeros que viajaron gratis y otros que pagaron 512 unidades monetarias de la época.
Al revisar las variables no numéricas se observa que de los 891 pasajeros analizados, el 65% corresponde a hombres 1.
#Describir las variables de tipo objeto
data.describe(include=['O'])
| Item | Name | Sex | Ticket | Cabin | Embarked |
|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 204 | 889 |
| unique | 891 | 2 | 681 | 147 | 3 |
| top | Campbell, Mr. William | male | CA. 2343 | G6 | S |
| freq | 1 | 577 | 7 | 4 | 644 |
Para saber cuántas mujeres y cuántos hombres sobrevivieron a la tragedia, se genera una tabla de contingencia para las variables sobrevivientes (survived) y sexo (Sex):
# Crear una tabla de contingencia
tabla_cross = pd.crosstab([data.Survived],[data.Sex])
tabla_cross
| Survived | female | male |
|---|---|---|
| 0 | 81 | 468 |
| 1 | 233 | 109 |
Se observa que la cantidad de sobrevivientes mujeres es mayor que los hombres. ¿Habrá relación entre el sexo de los sobrevivientes y la clase en que se viajó? La primera aproximación a esta respuesta se puede obtener a través de otra tabla de contingencia considerando las variables sexo y clase:
# Crear una tabla de contingencia para las variables Survived, Pclas y Sex
tabla_cross2 = pd.crosstab([data.Survived, data.Pclass],[data.Sex])
tabla_cross2
| Survived | Pclass | female | male |
|---|---|---|---|
| 0 | 1 | 3 | 77 |
| 0 | 2 | 6 | 91 |
| 0 | 3 | 72 | 300 |
| 1 | 1 | 91 | 45 |
| 1 | 2 | 70 | 17 |
| 1 | 3 | 72 | 47 |
Según la tabla, la mayor cantidad de sobrevivientes corresponde a mujeres que viajaron en primera clase y la mayor cantidad de fallecidos fueron hombres que viajaron en tercera clase.
¿Qué se puede decir respecto de las edades de los sobrevivientes?. Para dar respuesta a esta interrogante se hará uso de la visualización de datos a través de gráficas.
# Histograma para la variable edad según si sobrevivió o no a la tragedia
histograma_edad = sns.FacetGrid(data, col='Survived')
histograma_edad.map(plt.hist, 'Age', bins=20)
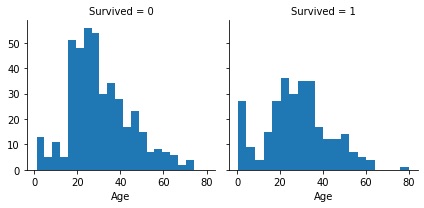
De la gráfica se desprende que los sobrevivientes son mayormente niños y adultos de entre los 20 y 40 años. Respecto de la edad y el sexo, no hay diferencias considerables que aporte este nuevo gráfico.
# Histograma para las variables edad y sexo según si sobrevivió o no a la tragedia
histograma_SyE = sns.FacetGrid(data, col='Survived', row='Sex', height=2.2, aspect=1.6)
histograma_SyE.map(plt.hist, 'Age', alpha=.5, bins=20)
histograma_SyE.add_legend();
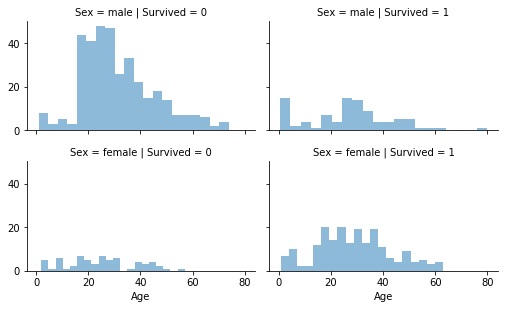
Si se analiza finalmente por edad y clase en la que se viajaba, se puede decir que para todas las edades la mayor cantidad de sobrevivientes son los que viajaban en primera clase.
# grid = sns.FacetGrid(train_df, col='Pclass', hue='Survived')
histograma_PcyE = sns.FacetGrid(data, col='Survived', row='Pclass', height=2.2, aspect=1.6)
histograma_PcyE.map(plt.hist, 'Age', alpha=.5, bins=20)
histograma_PcyE.add_legend();
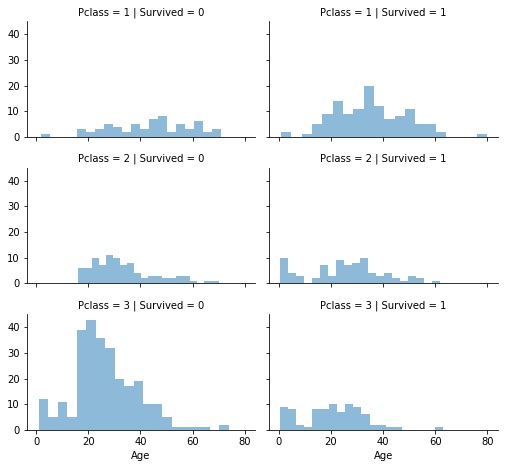
En esta primera parte, y de manera bastante rápida, se pudo obtener una visión general de los datos y acuñar las primeras hipótesis de correlación entre las variables. Por ejemplo, la edad, sexo y clase en la que se viajó están relacionadas con la posibilidad de haber sobrevivido a la tragedia.
En la segunda parte del proyecto se trabajará y presentará la correlación entre las variables y el modelo de predicción de sobrevivencia.
-
$% ,de ,hombres =\frac{512}{891}*100 = 65%$ ↩︎
Natalia Aros M.
Consultor
Me interesa aprender sobre programación, ciencia de datos, machine learning y tecnología en general.